Efficiently handles large-scale crawling tasks.
The right agency for your project providing success with every solution


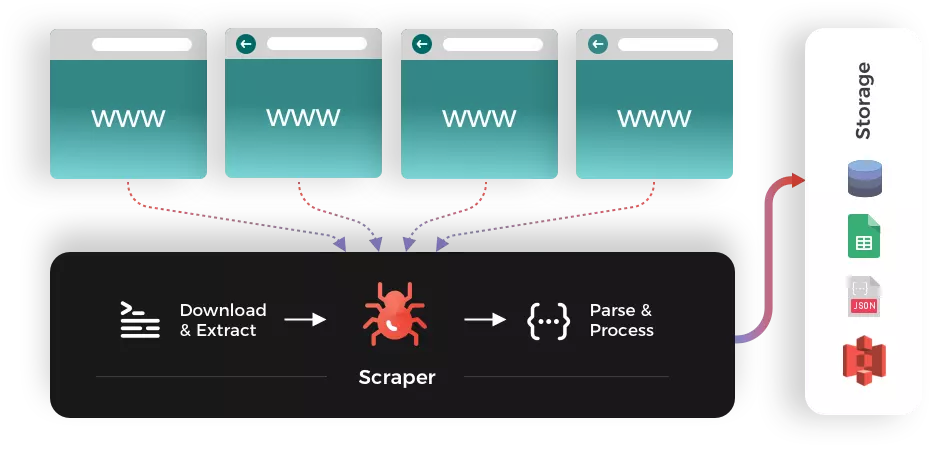
Harness the power of advanced web scraping technologies to transform vast, unstructured data into actionable insights. Take advantage of our tailored data scraping development service to unlock competitive advantages, drive strategic decisions, and fuel growth. Step into the future of data-driven success today.


The right agency for your project providing success with every solution
Tailor-made data scraper development for extracting data from various online sources, with a focus on precision and relevance to your business needs.
Advanced scraping of interactive and dynamic websites using technologies like Selenium, ensuring comprehensive data collection.
Custom-built, cloud-hosted scraping solutions with seamless API integration and user-friendly interfaces, designed for effortless data utilization in your business.
Code reliable APIs to seamlessly interface with backend and front-end applications, allowing them to communicate and share data efficiently.
We create a unique backend platform to meet your highly personalized project requirements, offering flexibility and scalability for diverse front-end applications.
Ongoing maintenance and support to keep your APIs and integrations running smoothly.
 Extract data from dynamic web sites
Extract data from dynamic web sitesExtracting data from web pages with dynamic loading, like those using JavaScript and AJAX, challenges us. We need special tools to render these pages correctly. These tools help us access the data created by client-side scripts.
Extracts data from websites with dynamic content loading.
Ensures proper page rendering through JavaScript execution.
Utilizes headless browsers to simulate realistic page interactions.
Handles AJAX requests and waits for the dynamic content to load.
 Export data in CSV, XLSX and JSON formats
Export data in CSV, XLSX and JSON formatsWe offer data export in CSV, XLSX, and JSON formats for broad compatibility. These formats integrate seamlessly with spreadsheets, databases, and web applications. This enhances the practical use of extracted data.
These formats support a range of software, from text editors to databases and apps.
CSV and XLSX optimize data analysis in tools like Excel or Google Sheets.
JSON's lightweight format enables efficient data exchange between systems and web apps
These widely recognized formats simplify data sharing, ensuring clarity and accessibility.
 Automate data extraction in the cloud
Automate data extraction in the cloudWe leverage cloud computing resources to automate data extraction, streamlining the process and enabling scalability. We eliminate the need for local infrastructure, allowing for automated scheduling, processing, and storage of extracted data.
Scale resources as needed to manage fluctuating data extraction volumes.
Eliminate local server and hardware maintenance, reducing costs.
Automate data collection at intervals or in real-time for fresh data.
Store extracted data in a centralized cloud repository, accessible anywhere.
 Integrate data with any system
Integrate data with any systemWe integrate extracted data with various systems to ensure seamless data flow and enable unified, data driven decision making. This integration utilizes APIs, webhooks, or direct database connections for smooth data transfer and interoperability.
Combine data from multiple sources into a single, comprehensive view.
Enable cross system analysis to uncover valuable insights.
Trigger actions and automate processes based on integrated data.
Provide a complete understanding for more informed business decisions.
At VOCSO, we specialize in web scraping to extract valuable information from diverse and complex unstructured data sources. With expertise in cutting-edge tools and frameworks, we ensure efficient, accurate, and scalable solutions that adapt to any data challenge. Our ethical and precise approach helps transform raw data into well-structured formats, ready for seamless integration into your workflow.
Efficiently handles large-scale crawling tasks.

Parses HTML and XML for precise data extraction.
Analyzes and refines scraped data for actionable insights.
Automates browser actions for dynamic content scraping.

Navigates anti-bot mechanisms with precision.
Enables fast, server-side HTML parsing.

Provides a robust foundation for scalable scraping solutions.
Simplifies browser automation for advanced scraping needs.
Overcomes IP restrictions and ensures uninterrupted scraping.
Seamlessly controls headless browsers.
Extracts data from images and PDFs.
Enhances data processing and extraction from natural language content.
Powers lead generation and sales prospecting by extracting customer and market data.
Acts as an automated data aggregator for collecting and organizing information from sources.
Extracts e-commerce product details and pricing information from online stores.
Automates the extraction of business listings and contact details from online directories.
Gathers real estate property listings, prices, and market trends for investment insights.
Extracts visual content, such as images, videos, and graphics, from websites.
Collects customer reviews, comments, and feedback from websites to analyze sentiment.
For businesses that need data consistently without the operational hassle, our Web Scraping as a Service (WSaaS) offers a fully managed, hands-off solution. This service is ideal for scenarios where maintaining, upgrading, and managing web scrapers isn't feasible or desirable.
With WSaaS, we take complete ownership of the entire data extraction lifecycle—from building and maintaining scrapers to managing proxies, hosting, and ensuring compliance. Businesses receive reliable, structured data at regular intervals without worrying about the underlying technology or infrastructure.

The client sought a comprehensive system for aggregating tee times available for sale across multiple golf clubs, each using different tee time booking software systems. The primary challenge was interfacing with these diverse systems. The objective was to create a solution capable of real-time searching, finding, and aggregating tee times available for sale and those sold within a specific time window. This platform served over 1,000 golf courses, enabling them to showcase their tee times and drive sales while effectively tracking transactions.

Schools18 exemplifies efficiency and innovation in the realm of educational search. The site's advanced APIs ensure rapid page loads, significantly enhancing user experience. This technical prowess is mirrored in the user engagement levels, with the portal quickly attracting a substantial daily active user base. Moreover, the robust and scalable nature of the APIs facilitated a comprehensive listing of schools, establishing Schools18 as a comprehensive and reliable resource.
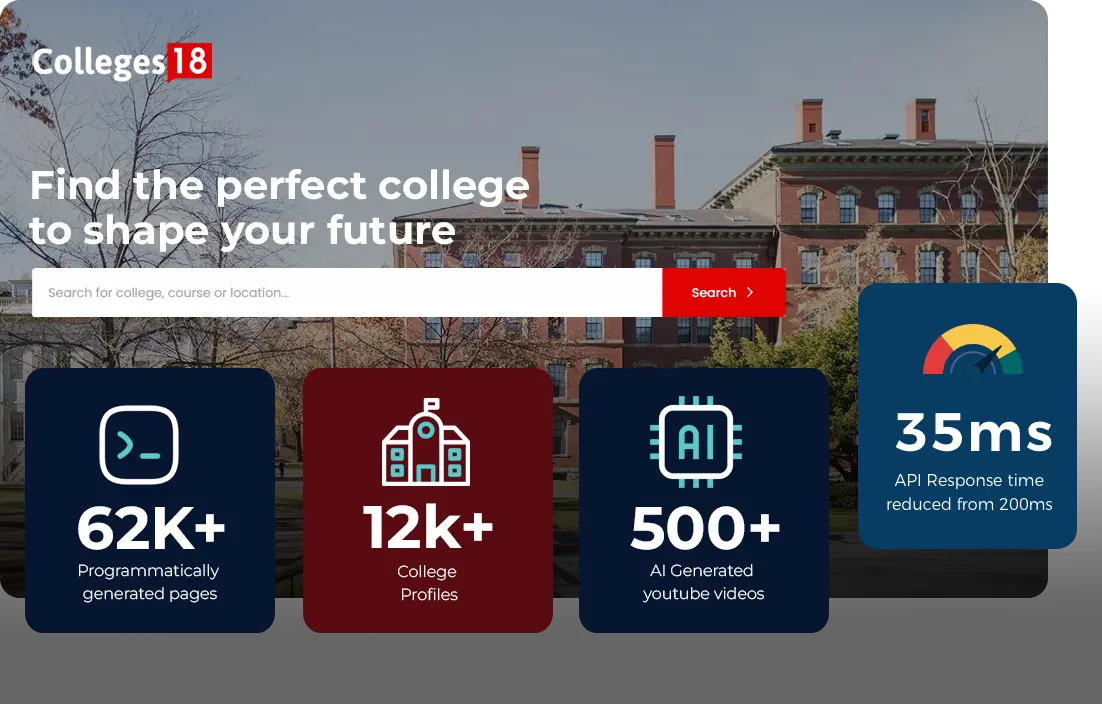
For Colleges18, we developed a college search directory website using Strapi with (PostgreSQL as database) and NextJs. This intuitive platform allows users to search and compare over 12,000 colleges across 200 categories in India efficiently.
Strapi provided a scalable CMS to handle extensive data, while NextJs’s powerful SSR capabilities helped generate SEO optimized pages and ensured fast and responsive user experiences. Within the first month of launch, the application generated over 500 leads. We developed custom plugins to automate certain workflows related to lead generation and kanban style ui for managing the same.


In pursuit of a more streamlined and efficient job application system, the client initiated a pivotal project aimed at the development of a feature-rich custom jobs module. The objective was to seamlessly integrate this module into their existing job application workflow. Achieving this ambitious goal hinged on the successful implementation of a robust backend development strategy and effective API integration.

"Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem."

"Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time."


"I am working with VOCSO team since about 2019. VOCSO SEO & SEM services helping me to find new customers in a small budget. Again thanks to VOCSO team for their advanced SEO optimization strategies, we are now visible to everyone."

"We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication. It was such a pleasure working with the team!"

"It was an amazing experience working with the VOCSO team. They were all so creative, innovative, and helpful! The finished product is great as well - I couldn't have done it without them"

"I want to take a min and talk about Deepak and Vocso team.We have outsourced web projects to many offshore companies but found Deepak understands the web content management and culture of US based firm and delivered the project with in time/budget . Also in terms of quality of product exceeds then anything else on which we work on offshore association I would recommend them for any web projects."

"Hi would like to appreciate & thanks Deepak & Manoj for the assistance any one thats look in to get web design They are very efficient people who can convert a little opportunity to fruitful association."

Understand your requirements and agree on commercials.
Based on thorough discussion and strategy
Add functionalities with plugins and customization
Make your website business ready
Perform complete quality checks and go live
Let's find out the right resources for you
Schedule a callEmbrace cutting-edge tools and libraries for sophisticated web and data scraping tasks. Harness the power of Python with libraries like Scrapy for efficient crawling, or leverage Beautiful Soup for intricate HTML parsing. For dynamic content, we consider Selenium or Puppeteer, offering unparalleled capabilities in handling JavaScript-rich sites.
Powerful python libraries such as Pandas, transform and analyze the scraped data with ease. Integrating these advanced tools elevates scraping projects, allowing us to tackle complex data extraction with precision and efficiency.
Python Scrapy: Ideal for creating high-speed crawling projects, offering both flexibility and power in data extraction.
Beautiful Soup: A must-have for intricate HTML parsing, making it easier to scrape data from web pages.
Selenium: Perfect for interacting with JavaScript-heavy websites, enabling dynamic content scraping with precision.
Puppeteer: Offers robust capabilities for automating browser tasks, crucial for scraping modern web applications.
Pandas: Transform and analyze your scraped data effectively, an indispensable tool for data processing and manipulation.
Requests: Simplify HTTP requests for web scraping, providing a more straightforward approach to data retrieval.
LXML: Fast and highly efficient library for processing XML and HTML, essential for parsing complex data structures.
Node.js libraries: Explore Node.js ecosystems like Cheerio or Axios for server-side scraping solutions.

Scraping web data also requires understanding of legal aspects of web data scraping is crucial to ensure compliance and avoid potential legal issues. It's essential to familiarize yourself with the laws and regulations surrounding data privacy, such as GDPR in Europe, and to adhere to the website's terms of service, which often dictate the permissibility of scraping activities.
Additionally, respecting intellectual property rights and acknowledging copyright restrictions play a significant role. Navigating these legal waters requires a careful, informed approach to scraping, ensuring that data collection and usage are both ethical and lawful.
Web scraping involves many obstacles such as CAPTCHAs, IP bans, and dynamically-loaded content, yet we effectively consider various strategies.
Overcoming CAPTCHAs: Consider CAPTCHA solving services on case to case basis. Sometimes it can be solved with OCR or AI tools for automatic recognition, and explore browser automation that simulates human interactions for bypassing CAPTCHAs.
Handling IP Blocks: Use rotating proxies to avoid IP bans and ensure continuous scraping, and opt for residential proxies for a more discreet approach.
Managing Dynamically-Loaded Content: Utilize tools like Selenium or Puppeteer for JavaScript-rich sites, and employ headless browsers to fully render dynamic content before scraping.
Avoiding Rate Limiting:Throttle requests to respect rate limits and schedule scraping during less busy hours to minimize rate limit triggers.
Data Quality Assurance: Implement post-scraping accuracy checks and continually validate and refine your scraping logic to keep up with source website changes.
It’s a crucial process that ensures the delivery of clean, structured, and reliable data for whatever your use case may be. We have developed a refined and efficient pipeline that encompasses several key stages. With that we aim to maximize the effectiveness of your data scraping operations.
Collection of Raw, Unstructured Data: Utilizing sophisticated scraping tools to efficiently collect relevant and high-quality unstructured data.
Pre-validation: Applying early-stage checks and automated scripts to eliminate irrelevant or incorrect data and correct common discrepancies.
Data Uploading to a Temporary Database: Safely transferring collected data to a temporary database, maintaining data integrity during the process.
Data Structuring and Uploading to the Main Database: Converting unstructured data into a structured format for analysis and transferring it to the main database for effective data management.
Validation, Review, and Manual Fixes: Performing extensive validation and manual reviews to ensure data accuracy and rectify any anomalies.
Deployment to the Working Data Environment: Seamlessly integrating processed data into the operational environment, ensuring its accessibility and utility for decision-making.
There are different use cases of data. However, the choice of data delivery method significantly impacts the ease of data integration and usage. Here are some of the most effective data delivery options:
APIs for Data Access:Consider APIs for a seamless, programmable approach to access your scraped data, enabling efficient integration with existing systems in real-time.
Leverage Webhooks:Utilize webhooks for instant data delivery to specific endpoints, perfectly suited for applications that demand immediate data updates or alerts.
Opt for Cloud Storage:Embrace cloud storage solutions like AWS S3 or Google Cloud for scalable, secure hosting, ideal for managing large data volumes with universal accessibility.
Direct Database Insertion:Directly insert scraped data into SQL or NoSQL databases, a recommended approach for applications needing frequent data interactions and analyses.
File Downloads (CSV, JSON, XML):Export data in formats like CSV, JSON, or XML for easy offline analysis, particularly useful when data sharing or standard tool analysis is required.
Data Streams Utilization: Implement data streaming through platforms like Apache Kafka for real-time processing and analytics, best for scenarios needing on-the-fly data handling.
Custom Solutions:For unique requirements, consider developing custom solutions, ranging from tailored APIs to specialized data delivery systems, ensuring a perfect fit for your specific needs
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Web scraping is the process of extracting important data from websites. It automates data collection, enabling market research, price tracking, competitor analysis, and more, ultimately leading to smarter, data-driven decisions.
We utilize a range of powerful tools like Scrapy, Selenium, Playwright, BeautifulSoup, and Cheerio to extract data efficiently. These technologies enable us to handle both static and dynamic websites, ensuring high-quality and accurate data extraction.
We provide data scraping solutions based on your business needs. After gathering data from various online sources, we process it using Python and nodeJS libraries to ensure the data is clean, structured, and ready for immediate use.
Yes, at VOCSO, we specialize in providing web scraping services at any frequency you require—whether it's daily, weekly, monthly, or any custom schedule that suits your business needs. We automate the solution to ensure data is collected consistently and accurately, helping you stay updated with fresh insights without manual intervention.
Web scraping can be utilized for a wide range of purposes, including but not limited to:
If you have a specific use case in mind, our team can tailor a web scraping solution to meet your unique requirements.
To avoid getting blocked, we use techniques like rotating proxies, user-agent rotation, and respecting the website's robots.txt file and rate limits.
We offer various data delivery options, including APIs, webhooks, cloud storage, direct database insertion, and file downloads (CSV, JSON, XML).
Yes, we specialize in scraping dynamic websites using advanced tools like Selenium and Playwright, which handle JavaScript, AJAX, and other dynamically loaded content to ensure comprehensive data extraction.
We leverage cloud computing resources to automate data extraction, streamlining the process and allowing scalability without the need for local infrastructure.
The challenges we primarily handle include managing CAPTCHAs, handling IP bans, dealing with dynamic content, and ensuring legal compliance.
Our web scraping services benefit a wide range of industries, including lead generation, e-commerce, real estate, directory scraping and more.
We integrate extracted data into your systems through APIs, webhooks, or direct database connections, enabling seamless data flow and ensuring smooth interoperability across platforms.




