

Web scraping has become an essential technique for extracting valuable data from websites, whether for business intelligence, market analysis, or academic research. However, one of the biggest obstacles that scrapers encounter is CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart).
CAPTCHAs are designed to prevent automated bots from accessing websites by requiring users to complete challenges that are easy for humans but difficult for machines. These challenges include identifying distorted text, selecting specific images, solving puzzles, or verifying user behavior.
Table of Contents
Types of CAPTCHAs and their challenges
There are several types of CAPTCHAs, each with unique challenges for web scrapers. Understanding these variations can help in selecting the right tools and techniques for bypassing them.
For web scrapers, handling CAPTCHAs is crucial because:
CAPTCHAs block automation: They disrupt web scraping processes and force manual intervention.
They slow down data collection: Each CAPTCHA challenge increases time delays.
Some CAPTCHAs track user behavior: More advanced CAPTCHAs use behavioral analytics (e.g., Google reCAPTCHA v3) to detect bots.
Text-Based CAPTCHAs
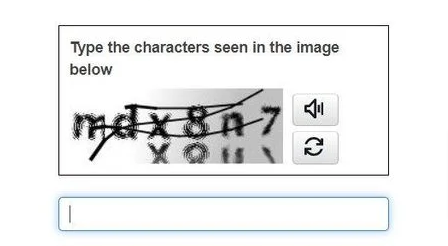
Text-based CAPTCHAs present users with distorted text, numbers, or a mix of both. Users must correctly type what they see to proceed. The distortion techniques include adding lines, warping letters, or using different fonts and backgrounds.
| Challenges for Web Scrapers | Common Solutions |
| Optical Character Recognition (OCR) tools like Tesseract struggle with heavy distortions. Some CAPTCHAs are case-sensitive, making them harder to bypass. | Using Tesseract OCR or OpenCV to preprocess images and extract text. Relying on CAPTCHA-solving services like 2Captcha, which use human solvers. |
Image-Based CAPTCHAs

These require users to select images matching a prompt (e.g., “Click on all the bicycles”). Google’s reCAPTCHA v2 and hCAPTCHA commonly use image-based verification.
| Challenges for Web Scrapers | Common Solutions |
| Image-based CAPTCHAs require visual pattern recognition, which is difficult for traditional OCR. Websites dynamically generate new images, making them difficult to store and reuse. | Using machine learning models like CNNs (Convolutional Neural Networks) for image recognition. Using browser automation tools like Selenium, combined with CAPTCHA-solving APIs. |
Audio-Based CAPTCHAs
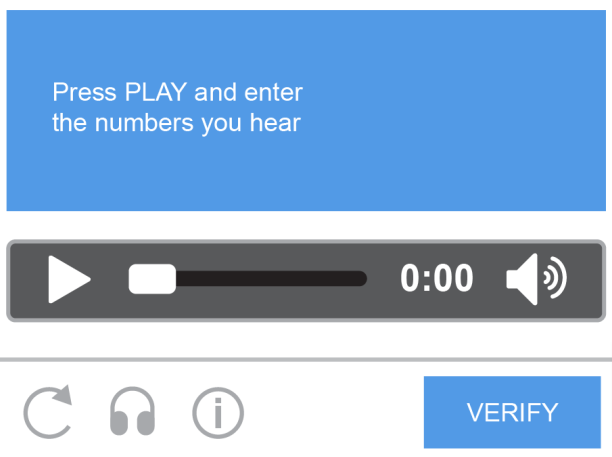
These CAPTCHAs provide an audio clip that users must transcribe. Used as an alternative for visually impaired users.
| Challenges for Web Scrapers | Common Solutions |
| Background noise and distorted speech make speech-to-text conversion difficult. Automated tools like Google Speech-to-Text API sometimes fail due to noise distortion. | Using speech-to-text AI models (Google Speech API, DeepSpeech). Sending audio to CAPTCHA-solving services that employ human solvers. |
reCAPTCHA (v2, v3, Enterprise)
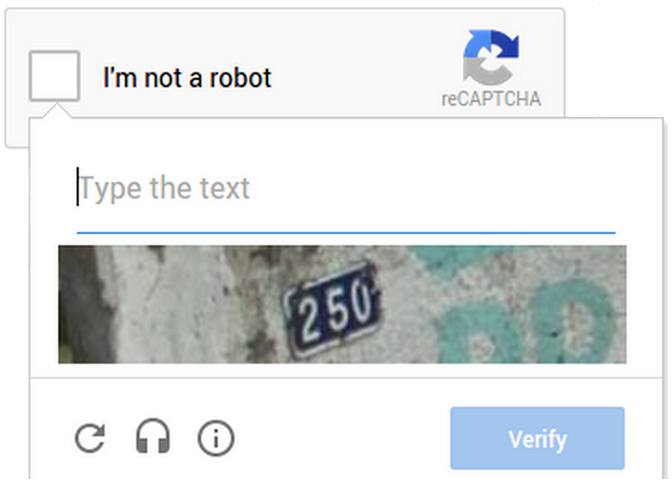
Developed by Google, reCAPTCHA is one of the most majorly used CAPTCHA systems.
- reCAPTCHA v2: Users solve image CAPTCHAs or check a “I’m not a robot” box.
- reCAPTCHA v3: Analyzes user behavior and assigns a “bot score” (low scores trigger verification).
- reCAPTCHA Enterprise: Even more advanced, tracking mouse movements, keystrokes, and IP history.
| Challenges for Web Scrapers | Common Solutions |
| Google constantly updates reCAPTCHA, making it harder to bypass. Behavior-based tracking means bots need to mimic human activity to pass. | Using reCAPTCHA bypass APIs like Anti-Captcha, 2Captcha. Employing browser automation tools like Playwright or Puppeteer to simulate human behavior. For reCAPTCHA v3, reducing bot score by integrating real user interactions (session cookies, valid user agents). |
hCAPTCHA
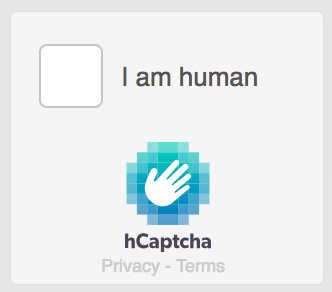
Similar to reCAPTCHA but focuses on human verification through more complex image challenges. Used by websites looking for an alternative to Google’s system.
| Challenges for Web Scrapers | Common Solutions |
| Harder to bypass than reCAPTCHA, as it generates unique and randomized challenges. Uses blockchain-based proof-of-humanity tests. | Using hCAPTCHA-solving services like CapSolver. Automating human-like behavior with Puppeteer or Selenium. |
JavaScript-Based & Invisible CAPTCHAs
Some CAPTCHAs do not display challenges but instead track user behavior (mouse movements, scrolling, time spent on page, typing speed, etc.). Modern Frontend Development techniques can help render dynamic web pages, reducing the risk of CAPTCHA triggers by ensuring accurate human-like behavior simulations. Invisible CAPTCHAs detect whether interactions resemble those of a bot.
| Challenges for Web Scrapers | Common Solutions |
| Scrapers that do not execute JavaScript (like Scrapy) are instantly detected. Headless browsers often trigger CAPTCHAs due to missing human-like interaction. | Running JavaScript in headless browsers using Playwright, Selenium, or Puppeteer. Using stealth plugins like undetected_chromedriver to avoid detection. Implementing behavioral emulation (simulating human-like mouse movements, delays). |
Techniques to Bypass CAPTCHAs
There are various techniques used to bypass these CAPTCHAs effectively.
These CAPTCHAs bypassing techniques can be broadly categorized into two types:
- Avoidance Strategies – Methods to prevent CAPTCHAs from appearing in the first place.
- Solving Strategies – Techniques to solve CAPTCHAs automatically when they appear.
By implementing a combination of both approaches, web scrapers can improve efficiency and minimize CAPTCHA-related disruptions. Also, implementing custom web development solutions allows for more tailored CAPTCHA-handling mechanisms, optimizing scraping workflows and minimizing manual intervention.
CAPTCHA Avoidance Strategies
Avoidance strategies focus on minimizing the likelihood of encountering CAPTCHAs while scraping a website. The key here is to ensure that the scraper mimics human behavior and avoids triggering bot detection systems.
Mimicking Human Behavior
Modern CAPTCHA systems (like reCAPTCHA v3) track user behavior to determine whether the visitor is a bot. Some best practices to mimic human behavior include:
Adding Random Delays:
Scraping too fast triggers CAPTCHAs. Introduce random time delays between requests. For eg.
import time
import random
delay = random.uniform(2, 5) # Wait between 2 to 5 seconds
time.sleep(delay)
Simulating Mouse Movements & Scrolling:
Bots usually interact with web pages statically, whereas real users scroll, move the mouse, and click elements.
Use Puppeteer or Selenium to replicate human-like actions:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://example.com")
actions = ActionChains(driver)
actions.move_by_offset(200, 100).perform() # Simulate mouse movement
Avoiding Headless Browsers:
Some sites check if a browser is running in “headless” mode and trigger a CAPTCHA if detected.
Use stealth plugins like undetected_chromedriver to bypass detection:
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get("https://example.com")
Using Proxies & Rotating IPs
Websites track repeated requests from the same IP and block them with CAPTCHAs. To prevent this, use proxy rotation techniques:
Residential Proxies:
These proxies mimic real user IPs, reducing the chances of being flagged.
Providers: Smartproxy, Bright Data, Oxylabs.
Rotating Proxies:
These proxies automatically change your IP address, making it appear as though requests are coming from multiple users, thus enhancing anonymity.
Eg. In Scrapy
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
PROXY_LIST = [
"http://user:pass@proxy1.com",
"http://user:pass@proxy2.com"
]
class ProxyMiddleware(HttpProxyMiddleware):
def process_request(self, request, spider):
request.meta['proxy'] = random.choice(PROXY_LIST)
Using a Proxy Manager like Scrapoxy:
scrapoxy startManaging Cookies & Sessions
Many CAPTCHAs track user activity through session cookies. Well streamlined Backend Development enables better session management and cookie handling, crucial for avoiding CAPTCHA triggers during repeated data requests. Some tips for managing cookies and sessions:
Reusing Cookies:
Instead of creating a new session each time, store and reuse cookies.
Eg. In Selenium
import pickle
driver.get("https://example.com")
pickle.dump(driver.get_cookies(), open("cookies.pkl", "wb"))
driver.get("https://example.com")
for cookie in pickle.load(open("cookies.pkl", "rb")):
driver.add_cookie(cookie)
Using Real Browser Sessions:
Instead of running a scraper in a separate environment, you can manually log in using a real browser and pass the session cookies to the scraper.
CAPTCHA Solving Strategies
If CAPTCHAs cannot be avoided, the next step is to solve them programmatically using automation tools, OCR, or third-party CAPTCHA-solving services. Leveraging efficient NodeJS Development techniques ensures smooth integration of CAPTCHA-solving services like 2Captcha and Anti-Captcha, especially when handling concurrent requests. By implementing proper custom API development, web scrapers can streamline CAPTCHA-solving processes and securely handle multiple verification challenges.
Using CAPTCHA-Solving Services (APIs)
Several paid services offer API-based CAPTCHA solving:
| Service | Features | Supported CAPTCHAs |
| 2Captcha | Low-cost, high success rate | reCAPTCHA, hCAPTCHA, text/image |
| Anti-Captcha | Supports automation frameworks | reCAPTCHA, invisible CAPTCHA |
| DeathByCaptcha | AI + human solvers | Complex image CAPTCHAs |
| CapSolver | Focus on hCAPTCHA | hCAPTCHA, image-based |
E.g Solving reCAPTCHA v2 with 2Captcha
import requests
API_KEY = "your_2captcha_api_key"
site_key = "6Lc... (found in site source)"
url = "https://example.com"
# Request CAPTCHA solving
captcha_id = requests.post("http://2captcha.com/in.php", data={
"key": API_KEY,
"method": "userrecaptcha",
"googlekey": site_key,
"pageurl": url
}).text.split('|')[1]
# Wait for the solution
import time
time.sleep(15)
solution = requests.get(f"http://2captcha.com/res.php?key={API_KEY}&action=get&id={captcha_id}").text.split('|')[1]
# Submit solution
requests.post(url, data={"g-recaptcha-response": solution})
Solving Text-Based CAPTCHAs with OCR (Tesseract)
If a CAPTCHA contains distorted text, OCR (Optical Character Recognition) can extract text automatically.
Step 1-Install Tesseract OCR (Eg. in Debain based systems):
sudo apt install tesseract-ocr
pip install pytesseract
Step 2-Extract Text from CAPTCHA Image:
import pytesseract
from PIL import Image
image = Image.open("captcha.png")
text = pytesseract.image_to_string(image)
print(text)
Handling Image-Based CAPTCHAs with AI
Using Convolutional Neural Networks (CNNs) to recognize images. Training AI models with TensorFlow or PyTorch to detect objects in CAPTCHA images.
import tensorflow as tf
from tensorflow import keras
model = keras.models.load_model("captcha_model.h5")
prediction = model.predict(image)
print(prediction)
Best CAPTCHA Solving Tools
There are different categories of CAPTCHA-solving tools based on the complexity of CAPTCHAs they handle. Modern Web Application Development practices incorporate CAPTCHA-solving automation to balance security and accessibility without disrupting user experience.
Some of the best captcha solving tools are:
| Tool | Type | Best For | Cost |
| 2Captcha | API-based | Text, reCAPTCHA, hCAPTCHA | $0.50 per 1000 CAPTCHAs |
| Anti-Captcha | API-based | reCAPTCHA v2, v3, Enterprise | $1 per 1000 CAPTCHAs |
| DeathByCaptcha | API-based | Image, text-based CAPTCHAs | $1.39 per 1000 CAPTCHAs |
| CapSolver | API-based | hCAPTCHA, reCAPTCHA Enterprise | Varies |
| Tesseract OCR | Open-source OCR | Simple text-based CAPTCHAs | Free |
| Puppeteer + reCAPTCHA Plugin | Browser automation | reCAPTCHA, hCAPTCHA | Free |
| Selenium + Undetected Chromedriver | Browser automation | JavaScript-based CAPTCHAs | Free |
| AI-Based Models (CNNs) | Deep Learning | Image-based CAPTCHAs | Custom |
Each tool has its strengths. API-based solutions are quick and easy, while browser automation tools work well for behavioral CAPTCHAs. AI models provide advanced image recognition for complex CAPTCHAs.
Implementing CAPTCHA Solving in Python
Now, let’s go through a step-by-step implementation using different methods.
Using 2Captcha API for reCAPTCHA v2
Many sites use Google reCAPTCHA v2 (the “I’m not a robot” checkbox). We can bypass it using 2Captcha API.
Steps:
Sign up on 2Captcha and get an API key.
Extract the CAPTCHA site key from the webpage source.
Send the request to 2Captcha API.
Retrieve and submit the solved token.
import requests
import time
API_KEY = "your_2captcha_api_key"
site_key = "6Lc_XXXXXXX" # Extracted from the website
page_url = "https://example.com"
# Step 1: Submit CAPTCHA for solving
response = requests.post("http://2captcha.com/in.php", data={
"key": API_KEY,
"method": "userrecaptcha",
"googlekey": site_key,
"pageurl": page_url,
"json": 1
}).json()
if response["status"] != 1:
print("Error submitting CAPTCHA")
exit()
captcha_id = response["request"]
# Step 2: Wait for the solution
time.sleep(15) # Give time for solving
# Step 3: Retrieve the solution
solution_response = requests.get(f"http://2captcha.com/res.php?key={API_KEY}&action=get&id={captcha_id}&json=1").json()
if solution_response["status"] != 1:
print("Error retrieving solution")
exit()
captcha_solution = solution_response["request"]
# Step 4: Submit the solution with the form
final_response = requests.post(page_url, data={"g-recaptcha-response": captcha_solution})
print(final_response.text)
Using Tesseract OCR for Text-Based CAPTCHAs
For simple text-based CAPTCHAs, OCR (Optical Character Recognition) can be used. Tesseract OCR is an open-source tool that extracts text from images.
Steps:
Install Tesseract OCR.
Preprocess the image (convert to grayscale, apply thresholding).
Extract text from the image using Tesseract.
import pytesseract
from PIL import Image
import cv2
# Load the CAPTCHA image
image = Image.open("captcha.png")
# Convert to grayscale
gray_image = cv2.cvtColor(cv2.imread("captcha.png"), cv2.COLOR_BGR2GRAY)
# Apply thresholding to improve OCR accuracy
_, processed_image = cv2.threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
# Extract text
text = pytesseract.image_to_string(processed_image)
print("Extracted CAPTCHA:", text)
Using Selenium & Undetected Chromedriver for JavaScript CAPTCHAs
Some websites use JavaScript-based CAPTCHAs that require real user interaction. We can use Selenium with undetected Chromedriver to solve these CAPTCHAs.
Steps:
Install undetected Chromedriver.
Use Selenium to automate form filling and bypass CAPTCHAs.
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
# Launch a stealth browser
driver = uc.Chrome()
driver.get("https://example.com")
# Find the CAPTCHA checkbox and click it
captcha_checkbox = driver.find_element(By.ID, "recaptcha-anchor")
captcha_checkbox.click()
# Wait for verification
driver.implicitly_wait(10)
# Submit the form
submit_button = driver.find_element(By.ID, "submit")
submit_button.click()
AI-Based CAPTCHA Solving (For Image CAPTCHAs)
For image-based CAPTCHAs, we can use machine learning models like Convolutional Neural Networks (CNNs).
Steps:
Train a CNN model with labeled CAPTCHA images.
Use TensorFlow/PyTorch to classify images.
Eg. Using TensorFlow to Classify CAPTCHA Images
import tensorflow as tf
from tensorflow import keras
# Load pre-trained model
model = keras.models.load_model("captcha_model.h5")
# Load CAPTCHA image
image = tf.keras.preprocessing.image.load_img("captcha.png", target_size=(100, 100))
image_array = tf.keras.preprocessing.image.img_to_array(image) / 255.0
image_array = image_array.reshape(1, 100, 100, 3)
# Predict the CAPTCHA
prediction = model.predict(image_array)
print("Predicted CAPTCHA:", prediction)
Ethical Considerations in CAPTCHA Bypassing
Bypassing CAPTCHAs means overriding security mechanisms that websites put in place. This raises ethical concerns, especially when scraping without permission.
When is CAPTCHA Bypassing Unethical?
Ignoring a website’s Terms of Service (TOS) – Many websites explicitly forbid scraping and CAPTCHA bypassing.
Scraping personal or sensitive data – Collecting emails, user accounts, or private information violates user privacy.
Excessively stressing a website’s servers – High-frequency scraping can slow down a website, impacting real users.
Automating fraudulent activities – Using CAPTCHA bypassing for fake registrations, ad fraud, or spam is unethical and illegal.
When is CAPTCHA Bypassing Justifiable?
Academic research – Some researchers bypass CAPTCHAs for public-interest studies (e.g., misinformation tracking, accessibility research).
Competitive analysis within legal boundaries – Extracting publicly available data for market research.
Data collection for personal use – Bypassing CAPTCHA for personal data aggregation (e.g., tracking flight prices) without violating policies.
Web archiving and public data access – Capturing information for historical or journalistic purposes.
Conclusion
CAPTCHAs are designed to stop bots, but with the right tools and techniques, they can be managed. Avoidance strategies, like rotating IPs and mimicking human behavior, help prevent CAPTCHAs from appearing. When solving is necessary, tools like 2Captcha, Tesseract OCR, and AI-based solvers can be useful. Choosing the right approach depends on the CAPTCHA type and the scraping goal.
At the same time, ethical and legal considerations should not be ignored. Scraping should always be done responsibly, following website rules and avoiding restricted or sensitive data. Whenever possible, using official APIs and respecting Terms of Service can help avoid legal complications. By combining tools and techniques with ethical practices, web scraping can remain both effective and sustainable.






